
Istnieje kilka sposobów na pracę w Excelu z większą liczbą rekordów niż 1 mln. Najnowsze z nich, wykorzystujące Power Query i Power Pivot, pozwalają na znaczną redukcję rozmiarów plików i przyspieszenie ich działania. Oto kilka przykładów z naszych eksperymentów przy realizacji usług związanych z automatyzacją raportowania oraz pobieraniem i transformacją danych z różnych źródeł.
Założenia eksperymentu
Eksperyment przeprowadziliśmy przy następujących założeniach:
- Programy: Excel 365 Pro Plus 32-bitowy, Power BI 64-bitowy
- Komputer: Procesor i7, pamięć RAM 8 GB, dysk SSD
- Plik źródłowy: 15 kolumn, 1 048 575 rekordów, rozmiar 110 MB
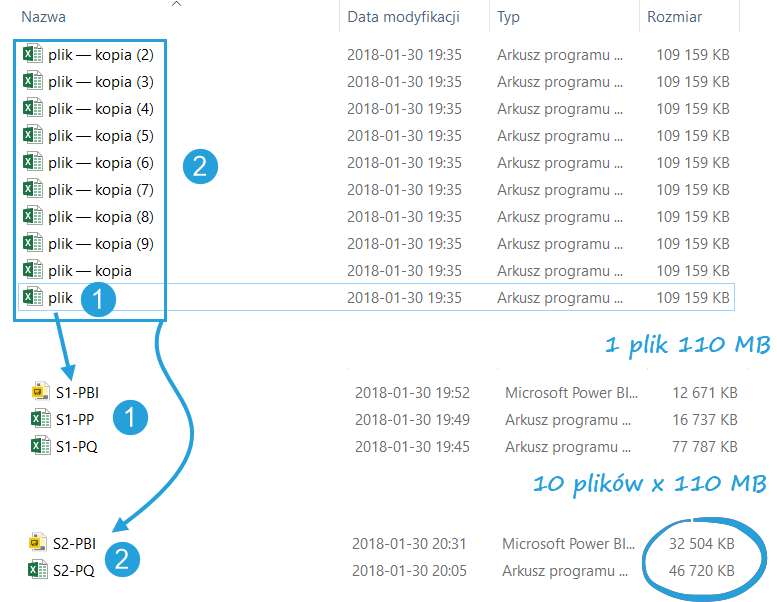
Scenariusz 1: 1 mln rekordów z pliku Excel
Pierwszy scenariusz polegał na wczytaniu 1 pliku Excel poprzez mechanizm Power Query. Plik ważył 110 MB. Plik wyczytywałem na 3 sposoby:
- PQ (Power Query > Tabela przestawna): czas pobierania 44 s, plik końcowy waży 78 MB
- PP (Power Query > Power Pivot > Tabela przestawna): czas pobierania 60 s, plik końcowy waży 17 MB
- PBI (Edytor zapytań > Model danych > Power BI): czas pobierania 44 s, plik końcowy waży 13 MB
Scenariusz 2: 10 mln rekordów z katalogu z 10 plikami Excel
10 plików bazowych waży łącznie ponad 1 GB (10 x 110 MB). Normalnie nie bylibyśmy w stanie pracować na takiej ilości danych w Excelu. Mechanizmy Power Query i modelu danych budowanego z użyciem Power Pivot nie mają z taką ilością większych problemów.
- PQ: po 11 min przy 8,5 mln pobranych rekordów pojawił się komunikat: Wystąpiły problemy z pobraniem danych
- PP: czas pobierania 6 min, plik końcowy waży 47 MB (przy 1 GB dla plików źródłowych!)
- PBI: czas pobierania 5 min 40 s, plik końcowy waży 33 MB (przy 1 GB dla plików źródłowych!)
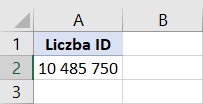
Oto zrzut liczby wierszy z Excela:
Wnioski końcowe
Kompresja danych, która odbywa się w modelu danych Excel i Power BI, potrafi wielokrotnie zmniejszyć rozmiar danych. Szczególnie widać w to w scenariuszu 2, gdzie z 1 GB danych uzyskaliśmy kilkadziesiąt MB. Co więcej, pliki były niesamowicie szybkie w pracy na modelu danych – wyniki w tabeli przestawnej pojawiały się od razu, nie było zawieszania, a ponieważ kalkulacje były napisane na modelu danych, również liczyły się znacznie szybciej. Wszystko za sprawą technologii in-memory, którą Microsoft nazwał xVelocity.
Jeśli Twoje raporty w programie Excel odświeżają się za długo, nie mieszczą się w arkuszu i nie pozwalają na szybką pracę z danymi, skorzystaj z tego, co w Excelu innowacyjne: ścieżki Power Query > Power Pivot > Tabela przestawna lub z aplikacji Power BI.




Nieźle 😀
Cześć Bartek mam pytanie – czy jesteś w stanie powiedzieć, z czego może wynikać relatywnie długie odświeżanie danych w tabeli przestawnej postawionej na danych z modelu danych w Power Pivot?, a jeszcze lepiej – jak ten czas odświeżania ograniczyć?
Dane są przetworzone w PQ i do PP załadowane mam tylko niezbędne kolumny. W PP mam utworzonych kilkanaście miar, które wykorzystuje w przywołanej tabeli przestawnej. Tabela występuje w pliku kilka razy (skopiowana, każda prezentuje inny układ danych), do tabel przynależą osobne fragmentatory.
Cały plik ma 1 426 KB, odświeżenie danych zajmuje ponad 15 minut i to obojętnie, w jaki sposób to robię. Czy jest coś, co mogę zrobić, żeby ten czas skrócić?
Hej Kasia, dziękuję za pytanie i od razu na wstępie napiszę, że nie da się zdiagnozować bez zobaczenia pliku. Wydaje mi się, że problem jest w Power Query i konstrukcji zapytań – dużo kroków, wolne źródła danych, może Excel 32-bitowy. Przyczyn może być wiele. Proponuję, żebyś przeszła przez checklistę z tego artykułu: https://skuteczneraporty.pl/11-pomyslow-jak-przyspieszyc-zapytania-w-power-query/. Jak to nie pomoże, możemy umówić się na Teams na analizę pliku.
[…] Więcej o przykładach poczytasz w eksperymencie z ładowaniem danych. […]